One of the big challenges in building software for Persistent Memory (PM) is software overhead: given the low latencies of PMs, any inefficiencies in the software show up prominently. This is true of PM file systems as well: every file-system operation must be efficient when performed on PM; otherwise, the low latency benefits of PM are squandered.
File systems such as PMFS and NOVA reduce software overhead by building a new file system inside the kernel. However, this approach suffers from two drawbacks: (1) overheads caused due to kernel crossings are left unaddressed and (2) building and maintaining a POSIX compliant file system is a difficult task; POSIX has a number of corner cases that are hard to get right. In this work, we try to answer the question, is it possible to minimize file system software overhead without creating an entirely new file system from scratch?
We present SplitFS, a new file system for persistent memory. SplitFS is available online at https://github.com/utsaslab/SplitFS.
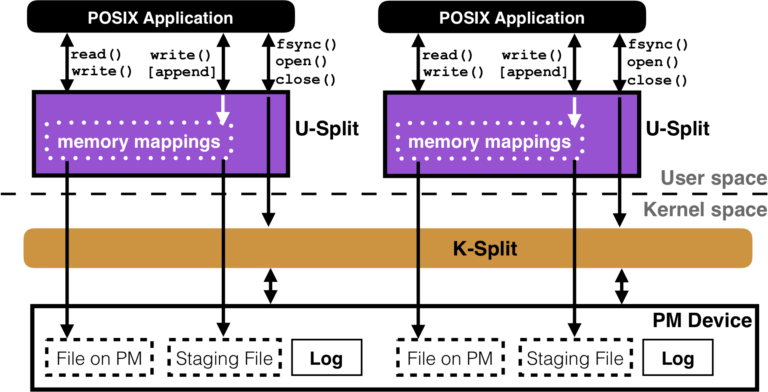
Split Architecture. SplitFS employs a novel split architecture. SplitFS consists of a user-space component, U-Split, and a kernel component, K-Split. SplitFS takes advantage of the fact that PM can be accessed via processor loads and stores since it is connected on the memory bus. SplitFS translates POSIX data operations (read and in-place write system calls) into user-space loads and stores on a memory-mapped file. As a result, these file-system operations enjoy low overhead and high performance.
POSIX metadata operations (like file close, open, appends, etc.) are handled by SplitFS’ kernel component. One of the unique aspects of SplitFS is that it uses an existing in-kernel file system, Linux ext4 (with DAX mode enabled), as its kernel component. All metadata operations are routed to ext4, relieving SplitFS of the complexity involved in accurately implementing POSIX. This design also means that SplitFS inherits the strengths and weaknesses of Linux ext4: as ext4 gets better, so does SplitFS. But the metadata operations of SplitFS will run at the speed of ext4. We believe that this trade-off is worthwhile since accelerating common-case data operations more than makes up for infrequent, slow metadata operations.
Another unique advantage of the split architecture is that SplitFS can allow applications running concurrently to obtain different consistency and durability guarantees from the file system without interfering with each other. This is possible because each application is linked to a different instance of U-Split. This feature becomes important since different applications want different guarantees from the underlying file system: for example, some applications may need atomicity guarantees for data operations while others may need only metadata atomicity. Tailoring the guarantees for individual applications can significantly improve application performance. For example, SQLite requires only metadata atomicity from the file system and additionally providing it with data operation atomicity (default option for NOVA) reduces its performance by 2x. To cater to different applications, SplitFS provides three different modes:
- POSIX mode: all metadata operations are atomic. This is similar to ext4 DAX.
- Sync mode: all operations are synchronous, in addition to metadata operations being atomic. This is similar to PMFS.
- Strict mode: all operations (including data operations) are atomic and synchronous. This is similar to Strata and NOVA with copy-on-write enabled.
To the best of our knowledge, SplitFS is the only file system to provide configurable durability guarantees to concurrent applications.
Relink. How is SplitFS able to provide strong guarantees while maintaining low overhead? At a high level, SplitFS performs logical logging plus a form of copy-on-write. Writes are not performed in-place, they are redirected to a temporary file. The temporary files are large (16 MB) and memory-mapped using 2 MB huge pages. The temporary files are also pre-faulted so that there is little overhead for reading a memory-mapped temporary file in the critical path. SplitFS introduces a new primitive called relink that atomically moves an extent of data from one file to another; relink is used to move the data in temporary files back to the original file. Relink logically moves extents without physically copying data: it is a pure metadata operation. Relink is done in a failure-atomic fashion by using the ext4 journal. We found relink to be a versatile and useful primitive: SplitFS uses it both for file appends and atomic file updates.
Logging. SplitFS logs all operations in sync and strict modes to ensure they are atomic, so an efficient logging mechanism is necessary for good performance. To reduce logging overheads, we reduce both the amount of data written to the log and also the number of expensive sfence instructions incurred while updating the logs. SplitFS uses logical redo logging. In the common case, each operation results in a single cache line (64 bytes) written to the log, followed by a single sfence instruction. The 64 byte log entry contains a 4-byte checksum, used to identify invalid or torn entries. The log entries do not contain data but simply point to a location in a temporary file that contains data for the operation. Each U-Split instance has its own log. Multiple threads coordinate access to the log via atomic compare-and-swap operations on the tail (maintained in DRAM). The tail is not persisted; upon a crash, valid entries are identified using checksums, and all valid entries are replayed. The log entries are idempotent, so replaying them multiple times does not cause incorrect behavior.
Overall, on a number of micro-benchmarks and applications such as the LevelDB key-value store running the YCSB benchmark, SplitFS increases application performance by up to 2x compared to ext4 and NOVA while providing similar consistency guarantees.
Lessons Learned. Our experience building SplitFS led to a number of interesting lessons about building systems for persistent memory:
- Page faults are expensive on PM. SplitFS memory-maps all files before accessing them, and a significant portion of the overhead is simply due to faulting in the pages with MAP_POPULATE. This overhead would not have been as significant on slower storage media (for example, NVMe SSDs or HDDs).
- Huge pages are hard to use. We found huge pages fragile and hard to use. Setting up a huge-page mapping in the Linux kernel requires a number of conditions. First, the virtual address must be 2 MB aligned. Second, the physical address on PM must be 2 MB aligned. As a result, fragmentation in either the virtual address space or the physical PM prevents huge pages from being created. For most workloads, after a few thousand files were created and deleted, fragmenting PM, we found it impossible to create any new huge pages. SplitFS works around this problem by efficiently re-using the huge-page mappings it creates. We believe this is a fundamental problem that must be tackled since huge pages are crucial for accessing large quantities of PM.
- Avoiding work in the critical path is important. Finally, we found that a general design technique that proved crucial for SplitFS is simplifying the critical path. We pre-allocate wherever possible, and use a background thread to perform pre-allocation in the background. Similarly, we pre-fault memory mappings and use a cache to re-use memory mappings as much as possible. SplitFS rarely performs heavyweight work in the critical path of data operation. Similarly, even in strict mode, SplitFS optimizes logging, trading off shorter recovery time for a simple, low overhead logging protocol. We believe this design principle will be useful for other systems designed for PM.
SplitFS is meant for POSIX applications that would like to benefit from PM without being rewritten from scratch. While SplitFS accelerates the performance of such applications, to fully take advantage of PM, applications will have to be rewritten using a framework like PMDK that exclusively operate on memory-mapped data structures.
We hope the design principles behind SplitFS prove instructive to developers. We are happy to help anyone who would like to try out and use SplitFS. More details including a tutorial on setting up SplitFS can be found here: https://github.com/utsaslab/SplitFS.
Vijay Chidambaram is an Assistant Professor at the University of Texas at Austin. He heads the UT Systems and Storage Lab, which aims to help create the next generation of storage systems.
Aasheesh Kolli is an Assistant Professor of Computer Science and Engineering at the Pennsylvania State University. His primary research interests are computer architectures and memory systems.
Rohan Kadekodi is a second year Computer Science PhD student at the University of Texas at Austin. He focuses on developing new storage software optimized for persistent memories.

This work by vijayc. is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 4.0 International