
The road so far
For the past few years the promise of persistent memory (PM) created a hype in research communities. The unprecedent possibility of persistent media being directly accessible by the CPU opens many opportunities to reconsider traditional architectural designs.
In this context, prior works proposed persistent data structures, such as range indexes (trees and its variants). While seminal contributions were made in terms of techniques and algorithms, the main weakness of these works was the lack of evaluation on real persistent memory hardware, since this was not available by the time. Nevertheless, common assumptions were often made, such as:
- Higher latency than DRAM, but within the same order of magnitude
- ~80ns (DRAM) vs. 160ns~700ns (PM)
- Asymmetric latency, writes being slower than reads
- Similar bandwidth to DRAM
- Cache-line access granularity (typically 64 bytes)
Based on these assumptions, the evaluations were usually performed on regular DRAM (no higher and asymmetric latency) or emulation platforms that introduced artificial latency to DRAM accesses (no asymmetric latency). Not only these approaches could not fulfill the expected behavior, but the release of Optane DC Persistent Memory Modules (DCPMM) showed that some of the assumptions made were not completely right. As an example, DCPMM bandwidth is not as similar to DRAM, and the access granularity has more idiosyncrasies than simply a cache-line. Still, PM has a lot of potential to disrupt modern system architectures.
In this context, we revisited prior works in order to reassess their contribution in view of the newly released DCPMMs[1]. We chose a representative subset of persistent range indexes proposed by prior work[2,3,4,5]. Each of the representants implement different techniques in order to cover a good portion of the design space. Since the original implementations differed a lot from each other and made different assumptions about the programming model, we re-implemented all of them in an unified way by using the same framework for persistent memory management (PMDK). Our goal was to isolate the impact of the techniques used by each index.
PiBench
One of the problems of comparing results across different papers is the different benchmark implementations and methodologies used, which are not always clearly documented. To aid in our evaluation, we created PiBench, a benchmark framework that enables a better understanding of the behavior of the indexes. PiBench has benefits over simply reporting the total runtime of a given workload:
- Metrics are collected over time intervals which allows a better visualization of the internal behavior within a single workload. This allows calculating statistics such as standard deviations in addition to averages. As an example, an insert-only workload is likely to have a higher standard deviation than update-only workload due to node splits and tree growth.
- Tools for accessing hardware counters (such as PCM) are integrated to better understand the index behavior, such as number of cache-misses, traffic between DRAM and PM, bandwidth, etc.
PiBench is open-source and available at https://github.com/tzwang/pibench. We are continuously improving it. Suggestions and contributions are welcomed.
Lessons Learned
In this post, we give a taste of three general lessons we learned in our evaluation of persistent range indexes.
Lesson 1
Read and write as less bytes as possible per operation. While this is an obvious statement, it becomes more important in the context of PM. Reducing the bytes read/written per operation is a guideline even in DRAM. However, an important observation is that index structures are commonly used in the context of a more complex and complete system. In these cases, the performance of the whole system is likely to hit other bottlenecks, such as network and NUMA, before saturating the available DRAM bandwidth. In the case of PM, developers placing DRAM index structures on PM might be disappointed with the performance, as the bandwidth is saturated much sooner and bottlenecks that were not visible before will be revealed.
This came as a surprise, as many previous works focused on evaluating indexes under different PM latency configurations in an emulation platform, but not many explored different PM bandwidths. In other words, while the higher PM latency was the biggest concern assumed in the past, it turns out that the limited bandwidth is really the villain here.
Recent work [6] also made this point very explicit. The authors propose a coroutine technique to hide latency of PM (here called NVM) accesses. One of the use-cases is improving the performance of binary search in a sorted array. The figure below shows that the proposed technique (Coro) achieves up to 5x lower latency for PM accesses in a single-core binary search.
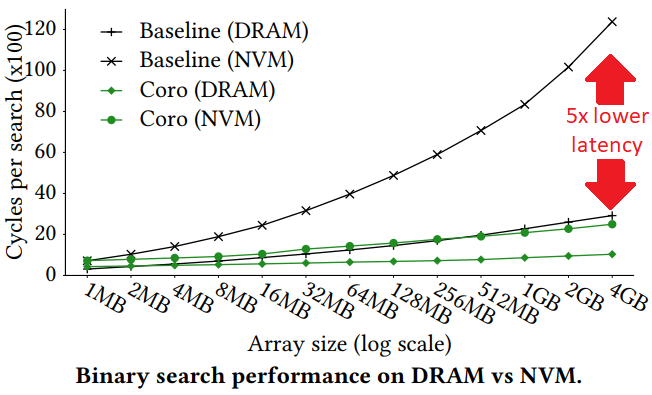
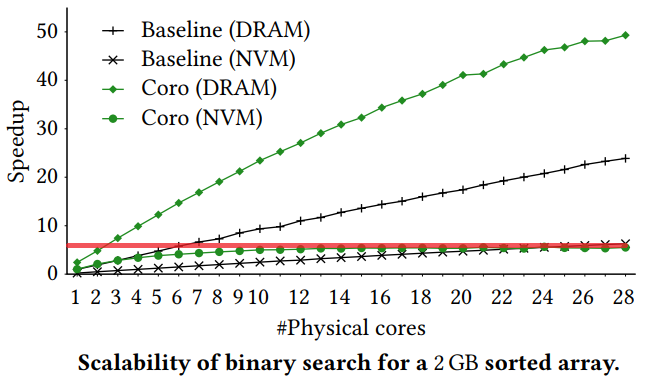
However, looking at the speedup for an increasing number of cores we see that the PM bandwidth is saturated only with a few cores (red line), after which the performance does not improve. Meanwhile, the same configuration on DRAM shows a more scalable behavior:
Lesson 2
Carefully consider the use-case before deciding for a setup. So PM is finally available and you are excited to buy yourself a DCPMM! How big should it be? How many should you buy? DCPMMs come in different sizes: 128 GB, 256 GB, 512 GB. These modules are directly attached to the memory bus alongside DRAM modules. Let’s consider a setup with 3 memory channels and 2 memory slots per channel. Usually only up to half the slots can be populated with DCPMM. It looks like this:
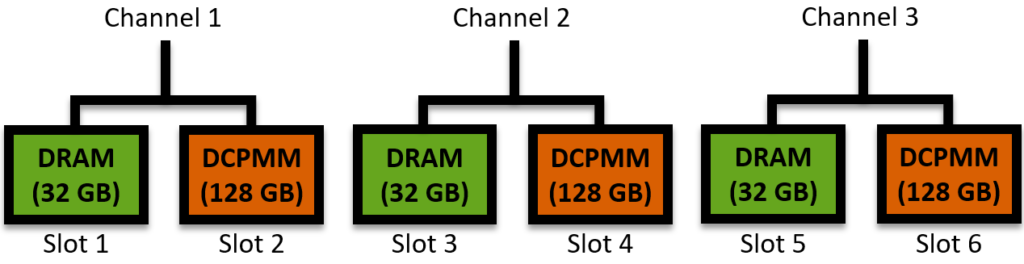
On one hand, DCPMMs are denser and therefore significantly increase the available physical memory on the system. Furthermore, they introduce persistence and potentially reduce power consumption. On the other hand, they occupy a memory slot that could otherwise be used by faster DRAM. Even in the case where additional DRAM modules will not increase the perceived bandwidth (if all memory channels are already populated, as above), one could still prefer additional DRAM modules to leverage its lower latency in the case of applications in which the response time is critical. For such scenario, this setup below could be more appealing:
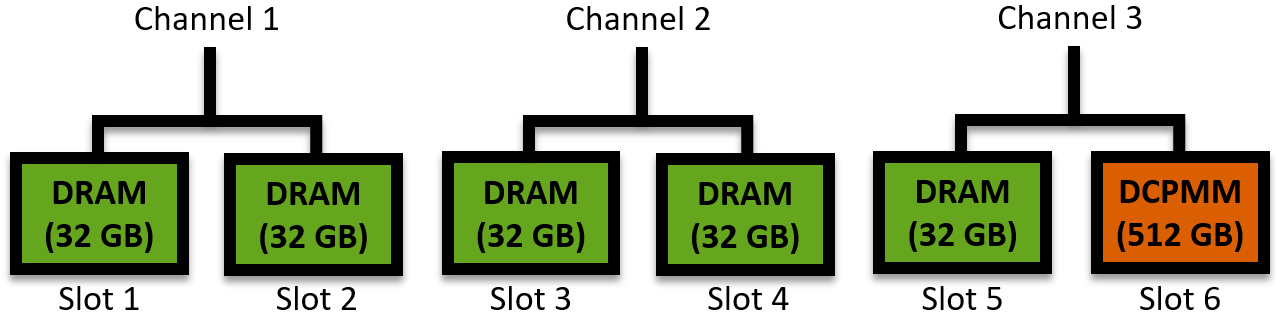
In this case, we replaced 2 DCPMMs for DRAM, and increased the capacity of the remaining DCPMM. It is worth noting that, even if the total PM capacity is even larger, the bandwidth achieved for PM access will be much lower, as only a single channel is used.
Another observation is that one should not buy additional DCPMMs to populate more channels and expect linear performance improvements out-of-the-box. In other words, 2 DCPMMs might not make your index structure be 2 times faster than with a single DCPMM. In our evaluation we observed that not all index structures presented the same gains when comparing a setup with 2 DCPMM (in 2 channels) vs. 6 DCPMMs (in 6 channels):
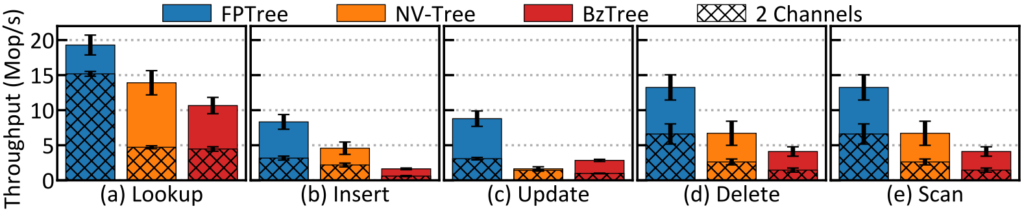
Therefore, one should always ask certain questions when deciding for a setup: How much PM do I need? How many DCPMM do I need? Is the use-case latency critical or bandwidth critical? How much data will be on DRAM and how much on PM?
Lesson 3
For the time being, PM should coexist with DRAM. The excitement provoked by PM led to proposals of systems, data structures, and algorithms that assumed a “single-level” architecture, i.e. PM would completely replace all memory and storage devices. Such assumption makes everything a thousand times more interesting and gets close to sci-fi. In this case one could achieve true instant recovery, or even challenge concepts such as “recovery”, “restart”, and “shutdown”. However, for the time being, PM technologies are neither cheap nor fast enough to completely replace DRAM, SSDs, HDDs, tapes, etc. Rather than that, PM should coexist with DRAM and the storage hierarchy.
To illustrate this point, two of the index structures we benchmarked are purely persistent (no use of DRAM), while the other two are hybrid (leaf nodes are places on PM, inner nodes on DRAM). In the figures below we see that even if the purely persistent indexes (wBTree and BzTree) achieve practically instantaneous recovery, they present a much lower performance and scalability during run time.
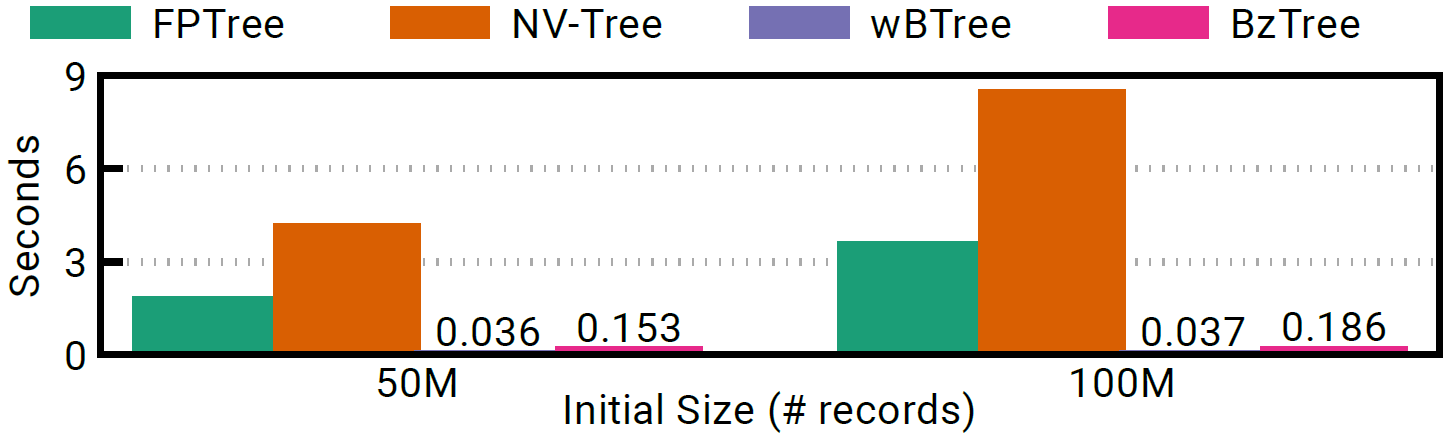
Recovery time.
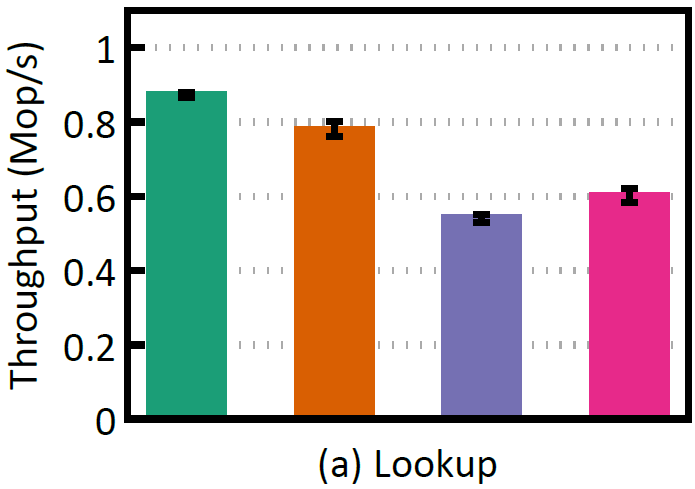
Runtime single-thread.
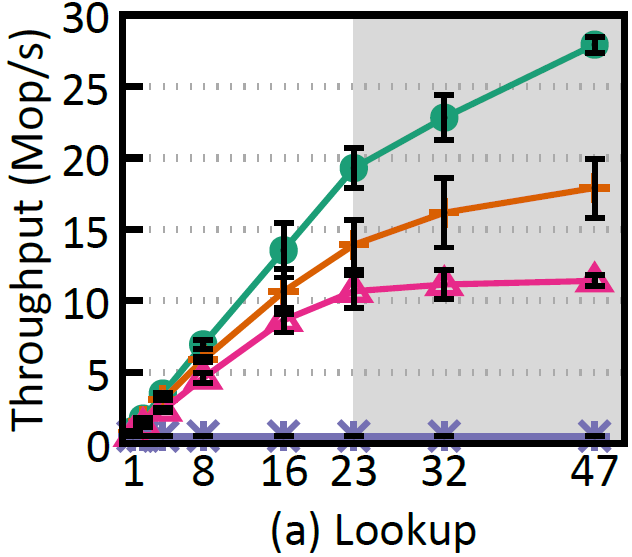
Runtime multi-thread.
Wishlist
Finally, the experience we acquired with our work made us wish for certain things when working with PM:
- Better performance: This is always something to ask for, but if a choice must be made between lower latency and higher bandwidth, we consider higher bandwidth is the priority for now. There are well-known software techniques for amortizing or hiding high latency (as mentioned earlier), but one can only go as fast as the bandwidth allows.
- Persistent CPU caches: One of the main challengers developers face with PM is the fact that at any point in time there can be a system or power failure and the contents of the CPU caches are lost. This requires pessimistically flushing data from the CPU cache to PM to enforce that no data is lost. Making CPU caches persistent will not only improve performance (no need to flush data back to PM all the time), but it will facilitate software development.
- Analysis tool: As new PM technologies evolve, it is important to understand the low-level idiosyncrasies of PM devices in order design systems to better leverage its performance. To this end, tools that allow analysing such characteristics are always welcomed.
References
[1] Lucas Lersch, Xiangpeng Hao, Ismail Oukid, Tianzheng Wang, Thomas Willhalm: Evaluating Persistent Memory Range Indexes. PVLDB 13(4): 574-587 (2019)
[2] Joy Arulraj, Justin J. Levandoski, Umar Farooq Minhas, Per-Åke Larson: BzTree: A High-Performance Latch-free Range Index for Non-Volatile Memory. PVLDB 11(5): 553-565 (2018)
[3] Ismail Oukid, Johan Lasperas, Anisoara Nica, Thomas Willhalm, Wolfgang Lehner: FPTree: A Hybrid SCM-DRAM Persistent and Concurrent B-Tree for Storage Class Memory. SIGMOD Conference 2016: 371-386
[4] Jun Yang, Qingsong Wei, Chundong Wang, Cheng Chen, Khai Leong Yong, Bingsheng He: NV-Tree: A Consistent and Workload-Adaptive Tree Structure for Non-Volatile Memory. IEEE Trans. Computers 65(7): 2169-2183 (2016)
[5] Shimin Chen, Qin Jin: Persistent B+-Trees in Non-Volatile Main Memory. PVLDB 8(7): 786-797 (2015)
[6] Georgios Psaropoulos, Ismail Oukid, Thomas Legler, Norman May, Anastasia Ailamaki: Bridging the Latency Gap between NVM and DRAM for Latency-bound Operations. DaMoN2019: 13:1-13:8
