
Thomas Shull (University of Illinois at Urbana-Champaign)
Summary
Byte-addressable, non-volatile memory (NVM) is emerging as a revolutionary memory technology that provides persistency, near-DRAM performance, and scalable capacity. However, to maximize NVM’s utility, software support is needed to ensure the desired data structures are placed in NVM and modified in a crash-consistent manner. Currently, the easiest way to interact with NVM is to use the Persistent Memory Development Kit (PMDK). Their framework has C & C++ APIs as well as a macro type system to allow users to create persistent applications; Java JNI bindings are provided as well in LLPL.
While PMDK is a nice framework, I believe that it places too much of a burden on the programmer. This is largely due to it being a library as opposed to a language extension. This burden is especially pronounced for Java programmers, who are accustomed to high-level abstractions and extensive built-in library support. Unfortunately, current NVM frameworks in Java require the user to add many markings to their application and are not compatible with existing libraries.
Given the current situation, in my research I have been working to enable crash-consistent programming in Java in a programmer friendly manner. Instead of creating a new framework, I have extended the language itself in order to ensure existing code can be handled persistently without prohibitive overheads. I call my new flavor of Java AutoPersist.
AutoPersist leverages persistence-by-reachability to assist the user in identifying which objects should be placed in NVM. By using this approach, the user has to add only one marking per a data structure to their program.
Below I describe AutoPersist in slightly more detail, but the main takeaway is that I have found that my model is both significantly easier to use and also has performance benefits over prior work. The performance benefits are due to the true language and compiler-level integration included in AutoPersist instead of a merely library support.
While AutoPersist definitely has room for improvement (see Section “Things I would change in AutoPersist”), my work has convinced me of two important takeaways:
- Current NVM frameworks are too complicated for mere mortals.
- Language and compiler support is necessary to create programmer-friendly, high performance software for NVM.
Current NVM Frameworks
Before diving into my contribution, I’d like to first give a quick overview of what NVM frameworks are available today. The primary framework is Persistent Memory Development Kit (PMDK), which is maintained by Intel. Oracle Labs also has worked on a framework named NVM Direct. Talks about both frameworks were also presented at PIRL this year if you are interested to learn more than the summary I present below.
These frameworks introduce a combination of macros, function calls, and new syntax (in the case of NVM Direct), in order to differentiate between the handling of volatile and persistent data. In this way, the user is able to allocate data into NVM as well as ensure writes are persistently completed. These frameworks also provide the user persistent logging support.
In the case of PMDK, there is also library support for some common data structures and use cases. This is necessary since these frameworks do not allow for existing libraries to be used persistently, as they will not have the necessary markings.
Frameworks for Java
Currently NVM support for Java is in a more preliminary stage. The primary option is to access NVM by using the PMDK library via the Java Native Interface (JNI). Intel has helped make this easier by introducing the Low Level Persistence Library (LLPL) for Java. In addition, they have made some simple Java data structures on top of LLPL and have bundled them into the Persistent Collections for Java (PCJ).
Relying on JNI has a lot of overhead, so LLPL and PCJ are not ideal. Luckily, JEP-352 has introduced into Java the ability to directly interact with NVM. This functionality can then be used to implement a new framework directly in Java without the need for JNI. This project is being led by Red Hat; to find out more, please visit their Github project and/or look at their slides from PIRL.
Limitations of Current NVM Frameworks for Java
When evaluating current NVM frameworks through the lens of a Java programmer, I found much to be desired. The first issue is that these frameworks rely on user input to identify persistent data and stores. As one can imagine, it is very easy to make mistakes while adding these markings to one’s code.
Another issue is that these frameworks cannot use existing built-in libraries persistently, as they do not have the needed markings. From my perspective, this makes these frameworks a non-starter for Java programmers. Java’s built-in libraries are an essential part of the Java programming experience and greatly help programmer productivity.
Finally, even with JEP-352, the allocated NVM memory is not part of the Java heap. This means that the user must manage objects’ lifetimes manually. In addition, since the NVM abstraction is a byte buffer, regular Java objects cannot be directly stored in it, which further hampers programmer productivity.
AutoPersist: Thoroughly Integrating Crash-Consistent Support into Java
Given the limitations of current frameworks, I set out to design a new approach for exposing NVM to Java. My goals were twofold: I wanted to 1) minimize the amount of markings a user has to add to code and also 2) ensure it would work well with existing libraries. In the end, I extended the Java runtime with features to handle much of the work needed to create crash-consistent applications internally based on a few user markings. Below I discuss AutoPersist’s programming model and how I implemented it within a Java Virtual Machine (JVM) implementation.
Model Overview
To understand AutoPersist’s programming model, it is important to understand how the following three items are accomplished:
- How is persistent data identified?
- How can stores be completed persistently?
- How can existing code be user persistently?
How is persistent data identified?
In AutoPersist, I use the notion of persistence-by-reachability to assist the user in identifying which objects should be placed in NVM. In this model, the user identifies root fields, i.e. entry points into persistent data structure. The runtime is then tasked with ensuring all objects transitively reachable from these fields are placed in NVM. The net effect of persistence-by-reachability is that one annotation is sufficient to ensure an entire data structure is placed into NVM. The images below demonstrate how by labeling one object as a durable root the entire data structure is made persistent. In my implementation, users can identify these roots for persistent data structure by choosing to annotate static fields with “@DurableRoot”. This annotation is then used by the runtime to enforce the persistence-by-reachability property.
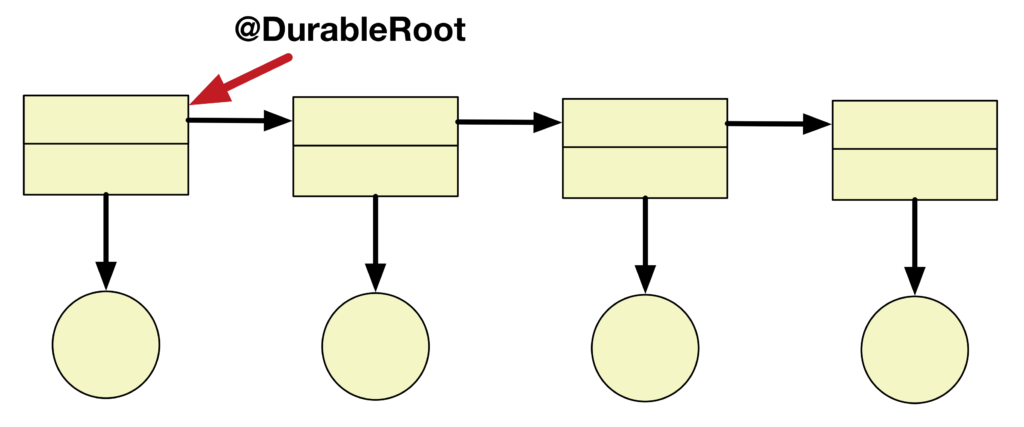
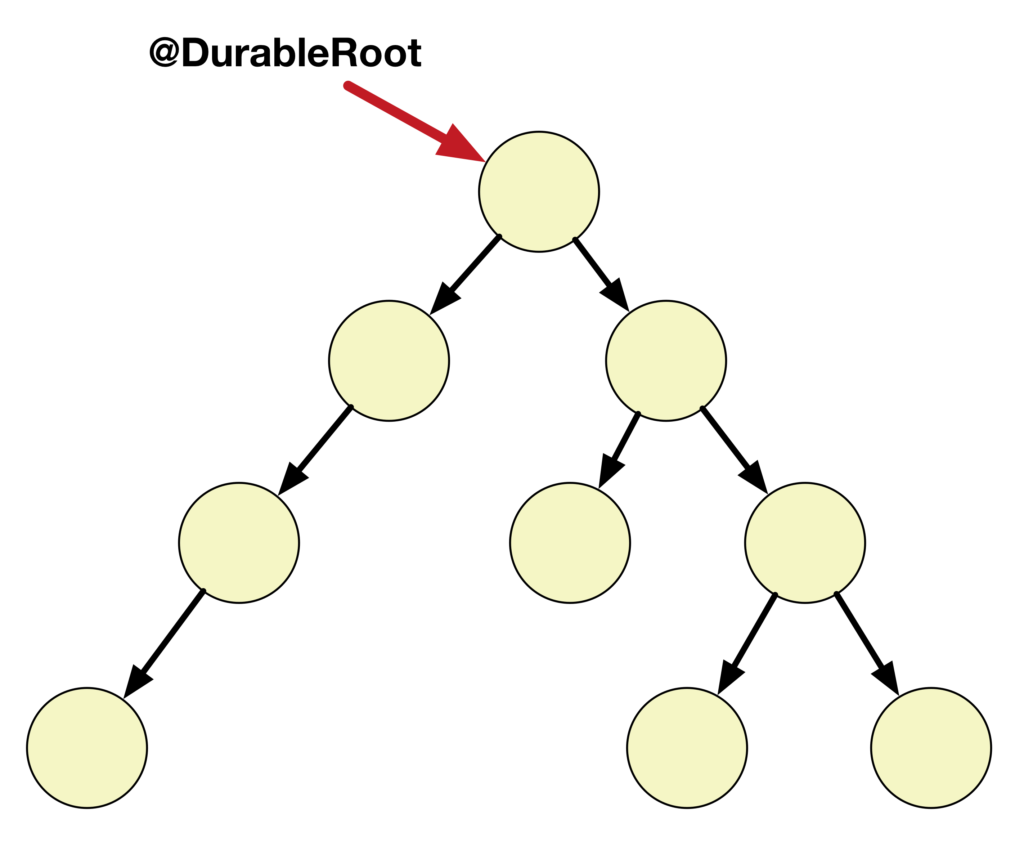
How can stores be completed persistently?
In AutoPersist the runtime is tasked with ensuring stores to objects in NVM are propagated to NVM. By default, AutoPersist ensures each write to NVM completes sequentially; however, it also provides an API for users to identify persistent transactions which are completed atomically by the runtime.
How can existing code be user persistently?
Java is a dynamically compiled language; put another way, machine code for a Java program is not generated until execution time. This allows AutoPersist to change the way machine code is generated to enforce AutoPersist’s requirements (persistence-by-reachability + persisting stores). Because all code, including built-in libraries, go through this execution-time translation, existing libraries will work correctly in AutoPersist without any changes to them. All which must happen is for their data structure to be reachable from a @DurableRoot.
Implementing AutoPersist in JVM
AutoPersist leans on the runtime to perform much of the heavy lifting of creating persistent applications. Because of this, many additions must be made to the JVM to enable AutoPersist. Note, however, that even with these changes, regular Java programs will run the same way as before. AutoPersist’s changes only appear when @DurableRoot(s) have been added to the program.
The first change was to create a new NVM heap space to hold persistent objects. All heap actions (allocation, garbage collection, etc.) also must be performed in a crash-consistent manner.
The next change was to add an extra header word to each object. I use this header word to assist with identifying which objects are reachable from a @DurableRoot and to detect when potentially a volatile object becomes reachable. When a volatile object is about to become reachable from a @DurableRoot, AutoPersist’s runtime more the volatile object and its transitive closure to NVM.
Finally, as I modified the semantics of many JVM bytecodes to potentially perform persistent actions, the compilers needed to be changed to follow the new semantics.
While I don’t have time to go over all of the details here, more details about how I implement AutoPersist are in this paper.
Optimizing AutoPersist
Because AutoPersist is integrated into the JVM, many optimization opportunities exist. As Java implementations already profile code throughout execution, it is natural to collect additional profile information about the application’s persistent behavior. This profiling information can then be used to optimize subsequently generated code. Currently, I use profile information to eagerly allocate objects in NVM and reduce the number of runtime checks, but many more opportunities are available. I also suspect new compiler passes can be added to further improve AutoPersist’s performance.
Things I would change in AutoPersist
While I am a believer in persistence-by-reachability and the need for programmer-friendly models, AutoPersist is far from perfect. If I were to start from scratch, the main change I would make would be to switch to using snapshot-based persistency. Currently, for persistency I provide a combination of logging and sequential writebacks. However, as AutoPersist has independent per-thread logging (which do not enforce isolation), it is possible to log an element into two different threads at the same time. In this situation, if the application were to crash, potentially incorrect data would be restored. To avoid this, the user is expected to add locks to their code to prevent this situation from occurring. However, this is not very programmer-friendly.
My current opinion is that having users request snapshots is a better idea. This is the approach being evaluated by Mario Wolczko (who also gave a talk at PIRL). However, note that I am still an advocate of persistence-by-reachability and believe this trait combined with versioning is probably the friendliest programming model.
Lessons Learned
Throughout my experience developing and testing AutoPersist, I have learned many lessons. The main one is that current frameworks are too tricky. In PMDK, it is too easy to make a mistake while labeling applications. PMDK’s simple design makes sense as first steps toward providing NVM support. However, as software becomes more mature (and there is more time to develop frameworks/models), a more programmer-friendly model is necessary. On the whole, I believe that the model should burden the runtime, not user, with responsibilities. My other thought is that for languages with a widely used set of built-in libraries, such as Java, it is very important that the built-in libraries can be reused in persistent applications.
Based on the above information, my conclusion is that creating frameworks for NVM is not enough. Instead, NVM support must be integrated into the language itself. This is necessary for the compiler and runtime to perform the optimizations needed in order to achieve high performance while using programmer-friendly NVM models. In addition, I believe that compiler support for NVM can be added which will greatly reduce the overhead of creating NVM applications.
More about AutoPersist
If you want to learn more about AutoPersist, currently I have two papers which detail aspects of its implementation. This paper highlights the main details about AutoPersist while this paper talks about one compiler optimization I performed on top of the baseline implementation.
Please feel free to contact me if you have other questions. You can find my contact information on my personal website.
Slides: https://pirl.nvsl.io/PIRL2019-content/PIRL-2019-Thomas_Shull.pdf
