
In this blog post, we describe how existing code can be adapted to store data interchangeably on DRAM or NVM in a way that is transparent to the code accessing the data. Programming concepts discussed include polymorphic allocators and fancy (i.e., non-T*) pointers.
Markus Dreseler (Hasso Plattner Institute, Potsdam, Germany)
Slides: https://pirl.nvsl.io/PIRL2019-content/PIRL-2019-Markus-Dreseler.pdf
Background
At HPI, we develop the columnar in-memory database Hyrise. It is an open-source system, written in C++, that serves at a platform for a number of research projects. These projects include database footprint reduction (making more data fit into memory), exploiting NVM for its capacity and durability benefits, partially replicating data across multiple database nodes to improve throughput, and making the DBAs job easier by allowing the database to self-tune important configuration parameters.
In NVM, we see two benefits: Firstly, its persistency allows us to store data without creating a second, persistent copy. Doing so helps us in reducing the time needed to restart the database after a planned or unplanned downtime from minutes or hours to seconds. Secondly, the higher capacity of NVM compared to DRAM allows us to fit more memory into a system, enabling us to build bigger in-memory databases. As accesses to data stored on NVM are slower than accesses to DRAM, our system needs to carefully select the appropriate memory type for different parts of the database. For example, data that is read rarely and where sequential reads allow the prefetcher to hide some of NVM’s latency is a good candidate for being placed on NVM, while heavily used data with random access patterns should remain in DRAM.
For our research, NVM is only one aspect amongst many. More people work on other components, and requiring them to understand the intricacies of NVM programming would place an additional burden on them. Thus, our goal is to make data structures NVM-aware without polluting the downstream interfaces.
Running Example
Throughout this blog post, we will work through an example that simulates an inverted index on a table:
std::vector<std::tuple<double /* column a */, int /* column b */>> table{
{4.2, 5},
{1.4, 7},
{3.5, 2}
};
using Value = double;
using Position = std::size_t;
using InvertedIndex = std::map<Value, Position>;
auto index = InvertedIndex{};
for (size_t position = 0; position < table.size(); ++position) {
index->emplace(std::get<0>(table[position]), position);
}
This is a heavily simplified example as databases usually do not use std::map (which is internally implemented as an rb-tree) for indexes. Also, other data structures are better candidates for being placed on NVM. Still, we like this example because the std::map is a bit more complex than a simple vector, while still being somewhat self-contained.
Having created the index, it is passed around the database and, for example, used when searching for a value in column a:
// Full table scan for a == 1.4, not making use of the index
// Complexity: O(n)
void table_scan(const Table& table) {
for (const auto& [a, b] : table) {
if (a == 1.4) std::cout << b << std::endl; // prints 7
}
}
// Index scan
// Complexity: O(log n)
void index_scan(const Table& table, const InvertedIndex& index) {
auto range = index.equal_range(1.4);
for (auto it = range.first; it != range.second; ++it) {
const Position row_id = it->second;
std::cout << std::get<1>(table[row_id]) << std::endl; // prints 7
}
}
Goals
Instead of always being on DRAM, this index should now optionally be placed on NVM. Such a decision might be made by the automatic tiering manager deciding that while the runtime savings of the index do not justify spending precious DRAM resources on it, it might be worth the additional memory usage when placed on more spacious NVM. In another scenario, the index is only used in certain time frames and is moved back and forth between DRAM and NVM.
From this context, we derive a number of goals: First of all, we want the data structure (read: STL container) to be placeable on both DRAM and NVM. This should happen transparently, so that existing code does not have to be adapted and new code does not become more complicated.
Secondly, we want to benefit from the persistency aspect of NVM. This means that indexes stored on NVM should be recoverable after a restart of the system. The requirements for this are well-known: Data must be flushed into the persistency domain, memory pointers must be functional even when NVM is re-mapped at a different virtual address, and allocations must not produce persistent memory leaks.
On the upside, we can relax the requirement of atomic modifications. This is due to our database system being insert-only: Instead of deleting or updating rows in-place, we mark the existing rows as invalid and insert new rows at the end. As such, most of the table will not change for a long time. By partitioning the table and building multiple indexes, we can have indexes on the static part of the table which, just like the indexed data, are created only once and will not change any time soon. What this means is that, different from most proposed NVM data structures, we do not require modifications to be atomic. Instead, we can simply create our index in one piece, mark it as finished, and never modify it again.
Replacing the default allocator with an NVM-aware allocator
As a first step, we want to modify our std::map to allocate memory on NVM. By default, STL containers retrieve their memory from operator new, which usually calls malloc next. This allocation strategy can be replaced with a custom allocator:
template <class T>
class nvm_allocator {
nvm_allocator() {
// create or load pool
}
[[nodiscard]] T* allocate(std::size_t n) {
return &pmem::obj::make_persistent<char[]>(n * sizeof(T))[0];
}
}
using InvertedIndexNVM = std::map</*[...]*/, nvm_allocator</*[...]*/>>;
Just like this, we have changed the existing code to allocate memory from NVM. It still has a number of issues, which we will tackle next.
While this new type behaves just like a regular std::map, its C++ type is incompatible. An InvertedIndex and an InvertedIndexNVM are two different things, meaning that the table now has to store two lists of indexes: Those stored on DRAM and those on NVM. Also, our index scan code from above would have to support two indexes: one with the default allocator and one with the NVM allocator:
void index_scan(const Table& table, const InvertedIndex& index);
void index_scan(const Table& table, const InvertedIndexNVM& index);
Erasing the allocator
The solution is to type-erase the allocator, i.e., to create a type that is compatible with both DRAM- and NVM-allocated indexes. For this, we build an allocator that internally knows whether to use DRAM or NVM memory but does not expose that information as part of its type.
template <class T>
class mixed_allocator {
mixed_allocator(bool use_nvm) : _use_nvm(use_nvm) {
// create or load pool
}
[[nodiscard]] T* allocate(std::size_t n) {
if (use_nvm) {
return &pmem::obj::make_persistent<char[]>(n * sizeof(T))[0];
} else {
return malloc(n * sizeof(T));
}
}
const bool _use_nvm;
}
using InvertedIndex = std::map</*[...]*/, mixed_allocator</*[...]*/>>;
auto dram_index = InvertedIndex(mixed_allocator</*[...]*/>(false));
auto nvm_index = InvertedIndex(mixed_allocator</*[...]*/>(true));
The drawback of this is that each allocator creates its own pool. Assuming one allocator per data structure (table, index, …), we easily end up with hundreds of pools, causing fragmentation of the available memory. Luckily, we were not the first to encounter this issue:
Allocators in C++ [..] have historically relied solely on compile-time polymorphism, and therefore have not been suitable for use in vocabulary types, which are passed through interfaces between separately-compiled modules, because the allocator type necessarily affects the type of the object that uses it.
This comes from C++ proposal N3916, which adds polymorphic allocators to C++. Instead of calling the allocator directly, these allocators rely on a memory resource, which they use to allocate and deallocate memory from. Memory resources can be shared across polymorphic allocators, which solves our fragmentation issue. Instead of storing a DRAM/NVM flag in our allocator, we can now use a polymorphic_allocator with a memory resource that draws from either DRAM or NVM:
using InvertedIndex = std::map</*[...]*/, polymorphic_allocator</*[...]*/>>;
auto& nvm = nvm_memory_resource::get();
auto nvm_index_1 = InvertedIndex{polymorphic_allocator</*[...]*/>{&nvm}};
auto nvm_index_2 = InvertedIndex{polymorphic_allocator</*[...]*/>{&nvm}};
// DRAM-based index uses default (DRAM) resource
auto dram_index = InvertedIndex{polymorphic_allocator</*[...]*/>{};
As you can see, two NVM-based indexes can share the same memory resource. Also, the C++ types of a DRAM- and an NVM-based index are now identical and the index lookup code does not need to know the storage location of the index anymore.
Even better, as memory_resource is a standardized interface, the index can now not only be placed on DRAM and NVM, but also on media like SSDs, graphic cards, or even be read via infiniband in a zero-copy mode; all without having to modify the implementation of index_scan.
Persisting data
So far, memory is taken from NVM but our writes are not persisted. If we were just interested in using NVM as some sort of pseudo-volatile memory with performance characteristics between DRAM and SSDs, we could stop here. However, most data in our database continues to be useful after a restart. If we do not persist the index, we have to rebuild it. This comes with a cost in the range of seconds or even minutes.
A modification (e.g., insert) of our rb-tree changes memory in different locations (e.g., nodes in the tree) with no regard for the ordering of operations. The tree is only guaranteed to be in a consistent state once the modification is completed and the execution returns to the caller. This does not only mean that the rb-tree is not thread-safe, but it also means that the all too well-known out-of-order execution and non-deterministic evictions of the CPU cache into NVM destroy any hope of making those single modifications NVM-atomic and durable.
In the beginning, we said that many data structures in databases are written only once. Now we are at the point where this knowledge comes into play. The creator of the index knows at which point the index is fully created and will not be modified anymore. They can then call the persist method on the allocator, which fully persists the index. From that point on, we can consistently restore it from NVM. In cases where we do not reach that point, we simply rebuild the index from scratch.
Still, we need to know which memory addresses need to be flushed. A simple solution would be to flush the entire NVM pool(s) allocated by the memory_resource, but this would flush more memory than necessary. Instead, we track the memory addresses that were given out by the allocator and the size of the allocation. The persist method uses that knowledge to call CLWB on the addresses used by the index and clears the list.
class polymorphic_tracking_allocator {
[[nodiscard]] T* allocate(std::size_t n) {
T* pointer = (T*)&pmem::obj::make_persistent<char[]>(n * sizeof(T))[0];
inflight_allocations.emplace_back(pointer, n);
return pointer;
}
void persist() {
for (auto& [p, n] : *inflight_allocations) {
pmemobj_persist(pool.handle(), p, n); // calls CLWB
}
inflight_allocations.clear();
}
// [...]
std::vector<std::pair<T*, size_t>> inflight_allocations;
};
Note that this is a modified polymorphic_allocator, not the original STL one. We do not remove entries from that list once the allocation is deallocated, as finding the entry would be more expensive than an unnecessary CLWB.
Preventing persistent leaks
While our index is now persisted on NVM, it might be more persistent than we want it to be. If the system crashes in the middle of the index generation, we are left with a number of allocations that have not been flushed and whose memory addresses might not even be stored anywhere. These persistent leaks would make the system unusable over time.
To counter this, we reuse the list of pending allocations that we originally introduced to be able to flush the data. By making this list persistent (replacing std::vector with pmem::obj::experimental::vector), we have an up-to-date list of pending allocations once the NVM pool is recovered. We just need to make sure that our allocations and the insertions into that list happen atomically. To do so, we can make use of pmemobj’s transactions:
class polymorphic_tracking_allocator {
polymorphic_tracking_allocator() {
root.inflight_allocations =
pmem::obj::make_persistent<pmem::obj::experimental::vector</*[...]*/>>();
}
[[nodiscard]] T* allocate(std::size_t n) {
T* pointer;
pmem::obj::transaction::run(pool, [&] {
pointer = static_cast<T*>(resource()->allocate(n * sizeof(T)));
root.inflight_allocations->emplace_back(pointer, n);
});
return pointer;
}
}
To keep the code example simple, we have left out the handling of DRAM memory-resources, which do not need tracking. Also, we keep only a single list of in-flight allocations instead of having one per allocator.
During recovery, if the list of in-flight allocations is not empty, the data structure that used the allocator has not been fully flushed and needs to be discarded. This is done by iterating over the list of pending allocations and freeing these memory regions.
Making the pointers position-independent
Sounds good so far? Unfortunately, we are still not able to recover the data after a restart. Similar to existing work on persistent data structures, we need to account for pointer addresses changing when the underlying memory is re-mapped. One of the more common approaches is to replace the raw T* pointer with a struct holding a base address or a heap identifier and an offset that is added on top of the base address. For example, PMDK 16-byte PMEMoid stores the pool UUID as well as an offset. For custom data structures built on top of PMDK, this is easy to use. However, as our goal is to use unmodified STL data structures, we need to find a way to plug these “fat pointers” into a standard std::map.
Again, the magic of C++ allocators comes to our help. Besides defining how ranges of memory are carved out of a heap, allocators have a number of member types that define how to interact with that memory. Amongst these is Alloc::pointer, which defaults to T*, but can also be defined as some fancy pointer. By replacing it with pmem::obj::persistent_ptr, and making our allocator return persistent pointers instead of T*, we can make the STL containers use this persistent_ptr instead of T* whenever they point to an internal data structure, such as a node in the rb-tree.
(Note: The cpp reference lists those member types as deprecated, which is because the preferred way to access them is via std::allocator_traits. In any case, the fancy pointers described here continue to exist.)
Unfortunately, not all of our indexes are stored on NVM. Data stored on DRAM does not have a PMDK pool UUID and cannot be referenced by a persistent_ptr. As such, we need a different approach to point to objects within our DRAM and NVM memory resources. We are not the first ones to run into this problem, but we have to look outside of the NVM world. In the case of Inter-Process Communication, processes map shared memory segments at different virtual addresses. Still, data structures stored in those segments should continue to be accessible.
This makes the creation of complex objects in mapped regions difficult: a C++ class instance placed in a mapped region might have a pointer pointing to another object also placed in the mapped region. Since the pointer stores an absolute address, that address is only valid for the process that placed the object there unless all processes map the mapped region in the same address.
To be able to simulate pointers in mapped regions, users must use offsets (distance between objects) instead of absolute addresses. The offset between two objects in a mapped region is the same for any process that maps the mapped region, even if that region is placed in different base addresses. To facilitate the use of offsets, Boost.Interprocess offers offset_ptr.
Source: Boost – Mapping Address Independent Pointer: offset_ptr
By using boost::interprocess::offset_ptr as the allocator’s pointer type, we can use relative addressing both for DRAM and NVM. You might wonder why this is not the default addressing mechanism for NVM. This is because it only allows for portable addressing of memory within the same heap. If two pmem pools are used, persistent_ptr can point from one pool to the other while offset_ptrs are only good within the same pool. For our use case, this is sufficient, as each memory_resource uses a single pmem pool.
template <class T>
class polymorphic_tracking_allocator {
public:
typedef T value_type;
typedef boost::interprocess::offset_ptr<T> pointer;
typedef const boost::interprocess::offset_ptr<T> const_pointer;
// [...]}
We can verify that this change allows us to remap NVM pools at different addresses by compiling our program as a position-independent executable (-pie).
Sounds almost too easy, right? Unfortunately, there is one big caveat. For this to work, the STL implementation needs to respect Alloc::pointer. This is done correctly by libc++, but libstdc++ ignores the allocator traits and continues to use T* for ABI (Application Binary Interface) compatibility reasons. As such, we can only use libc++ for now.
Performance
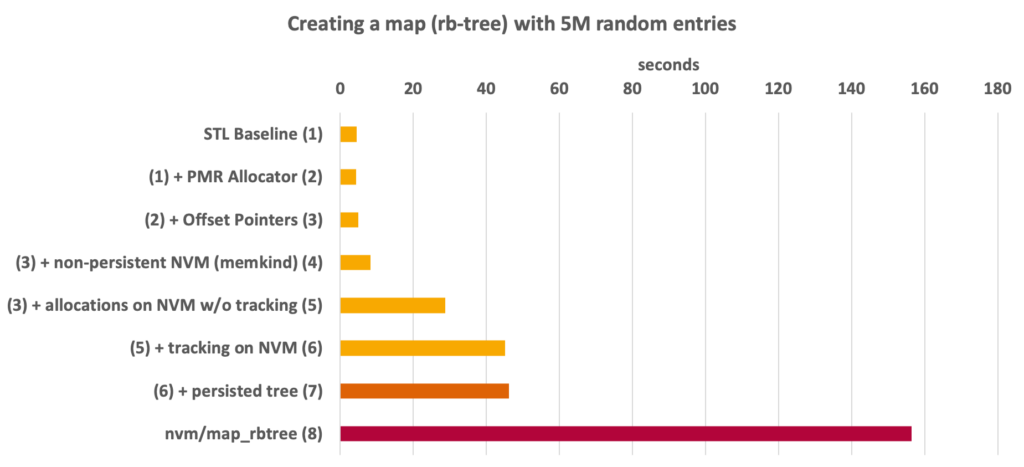
With all the magic happening in the allocator (virtual calls into memory resources, tracking allocations, pointer calculations for offset pointers), it is fair to ask how the performance is affected. We have added polymorphic allocators and offset pointers on top of the std::map. Those two are used both by NVM- and DRAM-based indexes, as they are what make our approach transparent. For NVM, we also need to use an NVM-compatible upstream allocator (one that does not produce leaks inside its own control structures). Furthermore, we need to track the allocations to be able to flush the data written by the std::map as well as to release it in case of an unsuccessful recovery. Finally, we need to actually flush the data once the index build has been completed.
In the graph, you can see these different steps for a benchmark where we create an rb-tree with five million entries. Step 1 is the unmodified std::map. Adding PMR (Step 2) and offset pointers (Step 3) to it while still keeping it on DRAM makes the index creation 13% more expensive. Step 4 shows the map being allocated on NVM in a pseudo-volatile configuration (which is outside the scope of this blog post). If we do not care about persistency, creating an NVM-based index is 65% more expensive than the same data structure on DRAM and 85% more expensive than an unmodified std::map.
Next, Step 5 is the first to use the PMDK allocator. This increases the cost by 2.5x and likely shows some potential for future allocators. Another cost is imposed on the data structure by having to track the allocations (Step 6), adding another 56%. Finally, calling persist() on the allocator adds the surprisingly little cost of just 2%.
Is this all worth the effort? We never expected it to be faster than an unmodified std::map and writing data to NVM is bound to be slower than on DRAM. As such, the more interesting comparison is against a fully-fledged NVM data structure. For this, we use map_rbtree from PMDK, which takes 2,39x longer to build. It is only an exemplary implementation of an rb-tree on NVM and other trees are better suited for NVM. Still, it gives us an idea on how much we can save by understanding the lifetime of the data structure and only having to flush it once.
What still needs to happen
While this works for us when measuring the performance impact of storing different parts of the database on DRAM and NVM, some challenges remain:
- NVM memory resources die together with the program. Recreating them requires additional meta structures, which hold the location of the pool file. For now, we circumvent this problem by using only a single, implicit pool file.
- The consistency of the persistency operations has not been stress-tested. It works sufficiently for our evaluations, but we would not yet trust it with our most valuable data.
On the C++ side, two changes would improve this and similar implementations:
- For now, this is limited to libc++. It would be great if libstdc++ added support for fancy pointers.
- Currently, loading C++ objects from memory is undefined behavior. This is more of a theoretical problem, but should be solved nonetheless. A proposed solution to this is std::bless.
Additional Resources
On Polymorphic allocations: https://www.youtube.com/watch?v=0MdSJsCTRkY
More information on PMR and memory resources: https://blog.feabhas.com/2019/03/thanks-for-the-memory-allocator/
On fancy pointers: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/p0773r0.html
